Les projets IA échouent rarement par manque d’algorithmes : la plupart des blocages viennent de la fragmentation des données, d’une architecture “reporting-first” et d’une gouvernance/temps réel insuffisants.
Pourquoi tant d'organisations restent bloquées au stade POC
Depuis quelques années, beaucoup d’organisations ont “coché les cases” : cloud, outils d’analytics, plateformes data, projets IA (dont IA générative), preuves de concept…
Et pourtant, le retour terrain est souvent le même :
- les projets mettent du temps à produire des résultats visibles,
- les cas d’usage restent limités à quelques POC,
- les décisions critiques se prennent encore via exports et fichiers Excel,
- les métiers ne sont pas pleinement confiants dans les chiffres.
Quand on gratte un peu, un constat revient systématiquement : ce ne sont pas les modèles d’IA qui bloquent, mais l’état des données sur lesquelles ils s’appuient. Gartner résume l’idée de façon brutale
“Everyone is ready for AI… except your data". (Gartner, State of Data Management 2024)
L’objectif de cet article : poser un diagnostic clair à partir de 3 constats très observables dans la majorité des systèmes d’information.
Vous avez coché toutes les cases… sauf une
Sur le papier, beaucoup d’organisations ont :
- un data lake, un data warehouse ou un lakehouse,
- une plateforme BI,
- des briques data science / ML / IA,
- des initiatives de gouvernance,
- des projets de modernisation applicative.
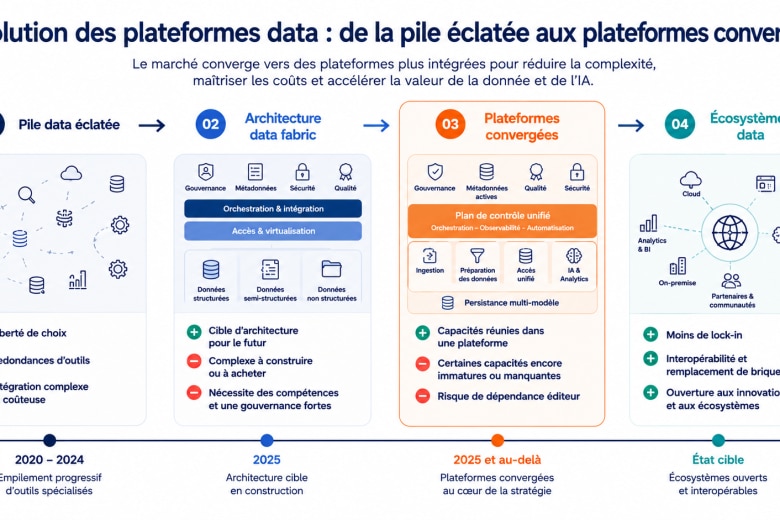
Mais la promesse initiale — décisions plus rapides, plus fiables, plus “intelligentes” — n’est pas totalement au rendez-vous. La raison tient souvent en une phrase : vous essayez de faire de l’IA sur un socle de données qui n’a pas été pensé pour ça. Gartner décrit un marché historiquement fragmenté (beaucoup de “point solutions”) et un mouvement de convergence qui vise explicitement à réduire la complexité et la charge opérationnelle. Avant de parler solutions, regardons les symptômes.
Constat n°1 : Vos données sont partout… mais jamais vraiment prêtes
Sur le papier, vous avez “plein de données” : applications cœur (ERP/CRM…), outils métiers, SaaS, fichiers, exports, bases spécialisées, datamarts…
Dans la réalité :
- une même information existe en plusieurs versions selon le système,
- personne n’est jamais totalement sûr de la “bonne” source,
- la donnée doit être retraitée avant chaque analyse un peu sérieuse.
Symptômes typiques
- Les équipes data passent un temps démesuré à réconcilier les données.
- Les métiers comparent les rapports et trouvent des écarts “inexpliqués”.
- Chaque nouveau cas d’usage IA redémarre par une préparation de données… de zéro.
Le problème n’est pas le volume. C’est la cohérence, la traçabilité, la qualité et le contexte. Et c’est précisément ce que recouvre la notion de “donnée AI-ready” : une donnée exploitable par l’IA, parce qu’elle est gouvernée, documentée et fiable.
Constat n°2 : Votre architecture a été conçue pour le reporting, pas pour l’IA
Beaucoup d’architectures data actuelles ont été conçues pour produire des rapports.
Schéma classique :
- collecter les données des systèmes opérationnels,
- transformer et charger dans un entrepôt / un lake,
- construire des vues / dashboards,
- livrer des rapports périodiques.
Pour ce modèle, batch nocturnes, copies multiples et quelques heures de latence n’étaient pas un problème majeur. Mais l’IA utile au quotidien (prioriser des commandes, ajuster une planification, détecter une anomalie, recommander une action, alimenter un agent IA…) impose autre chose :
- intégrer des données plus fréquemment (voire en continu),
- croiser des sources internes et externes,
- réagir à des événements,
- parfois décider en quelques secondes.
Là où ça casse
- Les copies se multiplient (ETL, exports, synchros, projets spécifiques).
- On sépare “opérationnel” (applications) et “analytique” (entrepôts/datamarts) → on ajoute de la latence.
- Dès qu’on rapproche l’IA du temps réel, la complexité explose : coûts, performance, sécurité, résolution d’incidents.
(En clair : une architecture “reporting-first” rend plus difficile le passage de l’IA du POC à l’industrialisation, surtout pour des cas d’usage opérationnels.)
Constat n°3 : Gouvernance et temps réel : les grands oubliés
Pendant longtemps, la gouvernance a été traitée comme un sujet de conformité, de catalogues “tenus à jour”, et de comités parfois vécus comme contraignants.
Avec l’IA, le sujet change :
- le nombre de sources explose,
- les usages se multiplient (y compris hors radar DSI),
- les risques augmentent : décisions biaisées, données sensibles, manque d’explicabilité.
En parallèle, beaucoup d’entreprises n’ont jamais vraiment industrialisé le temps réel : quelques flux ici ou là, une ou deux API temps réel, du streaming sur des cas ciblés… mais rarement une approche unifiée. Point clé : la donnée “AI-ready” n’est pas un projet ponctuel. C’est un cycle continu d’alignement, de qualification et de gouvernance.
Ce que ces 3 constats ont en commun
Ces constats décrivent un même problème : l’écart entre la donnée disponible et le moment où il faut décider.
Autrement dit :
- vos systèmes produisent de la donnée,
- mais l’organisation a du mal à en faire un actif fiable, traçable et réutilisable,
- et encore plus difficilement “temps réel”.
C’est précisément pour ça que Gartner parle de :
- convergence (réduction de complexité),
- inversion (les métadonnées au centre),
- et gestion du risque (notamment avec la GenAI).
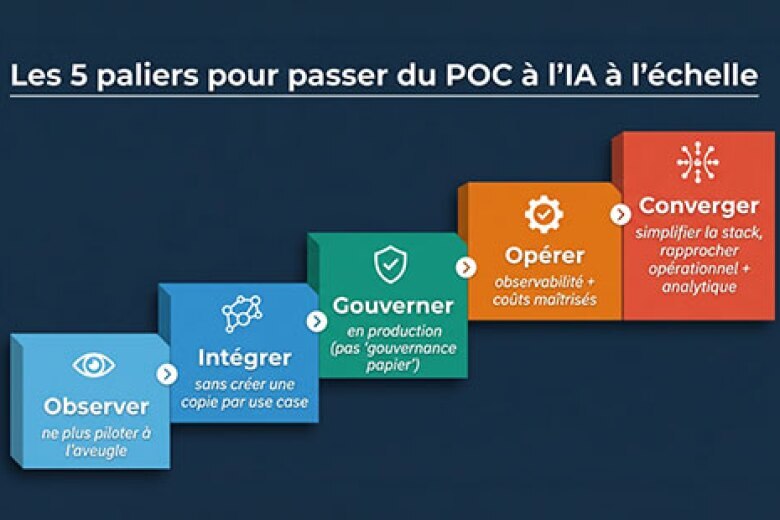
Les 3 freins qui bloquent l'IA au stade POC
Si vos projets IA patinent, ce n’est pas “un problème de modèle”. C’est presque toujours un mélange de données fragmentées, architecture pensée pour le reporting, et gouvernance/temps réel pas industrialisés.

5 questions simples pour évaluer votre situation
- Combien de temps faut-il pour rendre disponible une nouvelle source pour un cas d’usage IA ou analytique ?
- Combien de versions différentes d’un même indicateur critique (stock, marge, délai…) circulent ?
- À quelle fréquence vos modèles IA sont-ils ré-entraînés avec des données réellement à jour ?
- Qui peut dire précisément quelles données alimentent tel cas d’usage IA, avec quelles règles (droits, qualité, traçabilité) ?
- Combien d’équipes maintiennent leurs extractions et “datamarts Excel” en parallèle ?
Si ces questions font remonter plus de doutes que de réponses claires, ce n’est pas un échec de l’IA : c’est le signe que le socle data est devenu le facteur limitant.
Conclusion: la bonne question à se poser
La question n’est plus : « quel outil IA ajouter ? » mais : comment réduire la complexité et fiabiliser la donnée pour sortir du stade POC. Dans le prochain article, nous proposons une grille de lecture (convergence, data fabric, AI-ready data) pour se situer et distinguer une modernisation durable d’un simple empilement de briques.