



























Wählen Sie die richtige Plattform für Echtzeit-, operativ-analytische und KI-gestützte Workloads
Moderne datengesteuerte Unternehmen benötigen Plattformen, die Einblicke in Echtzeit liefern, KI- und GenAI-Initiativen unterstützen und einen geregelten, sicheren Zugriff auf konsistente, vertrauenswürdige Daten gewährleisten, ohne weitere Datensilos zu schaffen.
InterSystems IRIS® und InterSystems Data Studio™ wurden speziell für diese Anforderungen entwickelt und ermöglichen es Unternehmen, Daten aus verschiedenen Quellen in einer einzigen, KI-fähigen Echtzeitplattform zu integrieren und zu harmonisieren.
Databricks hingegen ist eine Analyse- und ML-Plattform, die für die Batch-Verarbeitung im Cloud-Maßstab, Data Science und Modelltraining in Data Lakehouse-Umgebungen optimiert ist.
Obwohl diese Plattformen unterschiedliche primäre Anwendungsfälle bedienen, können sie sich hervorragend ergänzen. InterSystems stellt vertrauenswürdige, kontrollierte Daten in Echtzeit für Analysen und Modellierungen in Databricks bereit. Databricks ermöglicht währenddessen die Entwicklung und Wartung großskaliger analytischer Modelle, die in Echtzeit in vernetzte, operative Workflows innerhalb von InterSystems integriert und dort eingesetzt werden können.

Die Schlüsselattribute im Vergleich
Attribut |
InterSystems |
Databricks |
| Primäre Nutzer | Anwendungsentwickler, Integration Engineers, Data Engineers, Data Stewards, Analysten | Data Engineers, Data Scientists, Machine Learning Engineers |
| Primäre Workloads | Optimiert für operative und analytische Echtzeit-Workloads mit hoher Performance (ACID-konforme HTAP-/translytische Verarbeitung) | Optimiert für Batch-Verarbeitung und Analysen; nur eingeschränkte Echtzeitunterstützung |
| KI-fähige Single Source of Truth | Die Data-Fabric-Architektur ermöglicht einen dynamischen, konsistenten Echtzeit-Zugriff auf unterschiedliche Quellen, ohne dass Daten dupliziert werden müssen, um eine KI-fähige Single Source of Truth zu schaffen | Optimiert für Batch-Analyse-Workloads, nicht als KI-fähige Single Source of Truth in Echtzeit |
| Flexibilität bei der Bereitstellung | Unterstützt lokale, öffentliche und private Clouds sowie hybride Deployments | Nur für die Cloud (Azure, AWS, GCP) |
| Lakehouse-Unterstützung | Unterstützt leistungsstarke Echtzeit- und Batch-Lakehouse-Anwendungsfälle | Pionierarbeit bei der Lakehouse-Architektur; optimiert für analytische, nicht operative Arbeitslasten |
| Multimodell-Unterstützung | Unterstützt eine Vielzahl von Datentypen und -modellen ohne Duplizierung oder Mapping, darunter relationale, Key-Value-, Dokument-, Text-, Objekt- und Array-Daten uvm. | Optimiert für in das Delta Lake-Format umgewandelte Daten |
| Low-Code / No-Code Schnittstellen | Einheitliche Benutzeroberfläche mit integrierten Low-Code- und No-Code-Tools | Primär code-first; Spark-Kenntnisse und Skripterstellung in der Regel erforderlich; minimale Low-Code-Unterstützung |
| Leistung in großem Maßstab | Nachgewiesene extrem hohe Leistung in geschäftskritischen, stark regulierten Branchen (z. B. Gesundheitswesen, Finanzwesen, Behörden) für betriebliche, analytische und betrieblich-analytische Workloads in Echtzeit | Hohe Leistung mit Photon für analytische Workloads; nicht optimiert für Anwendungsfälle mit geringer Latenz. Leistungsprobleme bei der Skalierung mit Neon DB. |
| Operationale Einfachheit | Integrierte Plattform und Dienste vereinfachen Bereitstellung, Konfiguration und Verwaltung | Erfordert die manuelle Einrichtung von Clustern, Aufträgen und Orchestrierungspipelines |
| Sicherheit und Governance | Integrierte Governance und Sicherheit für virtuelle und persistente Daten; branchenspezifische Funktionen für Gesundheitswesen, Behörden und Finanzdienstleistungen | Eingebaute Governance über Unity Catalog; komplexe Einrichtung erforderlich |
| Echtzeit-Streaming / Ingestion | Native Unterstützung für Echtzeitquellen; extrem niedrige Latenz für Ingestion und gleichzeitige Analysen von Echtzeitdaten | Structured Streaming und Auto Loader verfügbar; hohe Latenz für die Analyseverarbeitung von Echtzeitdaten |
| Modellbereitstellung / MLOps | Operationalisierung von Modellen aus beliebigen Frameworks, einschließlich Databricks, direkt in verbundene Live-Workflows | End-to-End-Unterstützung des ML-Lebenszyklus durch Integration mit Open Source MLflow |

Komplementär, nicht konkurrierend
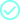
InterSystems und Databricks
InterSystems und Databricks ermöglichen eine vollständige Pipeline von Rohdaten bis hin zu KI-gesteuerten Entscheidungen und Maßnahmen in Echtzeit.
