

























现代数据驱动型企业需要这样的平台:能够实时提供洞察,支持人工智能与生成式人工智能(GenAI)项目,并在确保受控、安全访问一致且可信数据的同时,不增加新的数据孤岛。
InterSystems IRIS® 和 InterSystems Data Studio™ 专门为满足这些需求而设计,使企业能够将不同来源的数据整合并统一到一个支持人工智能的实时平台中。
相对而言,Databricks 是一个分析和机器学习平台,针对数据湖环境中的云规模批处理、数据科学和模型训练进行了优化。
虽然二者核心应用场景不同,但具有高度互补性。 InterSystems 可为 Databricks 中的分析和建模实时提供可信、受控的数据,而 Databricks 则可开发和维护大规模分析模型,并将其部署到 InterSystems 中的实时、连接、操作工作流中。

核心能力对比
特性 |
InterSystems |
Databricks |
| 主要用户 | 应用程序开发人员、集成工程师、数据工程师、数据管理员、分析师 | 数据工程师、数据科学家、机器学习工程师 |
| 核心工作负载 | 优化实时高性能运营分析型(ACID兼容HTAP/Translytical)场景 | 专注批处理分析与数据科学;实时能力有限 |
| AI就绪的单一数据源 | 数据编织架构可实现跨不同来源的动态、一致、实时访问,无需重复数据,从而创建一个可用于AI的单一数据源 | 针对批量分析工作负载进行了优化;非AI就绪的实时单一数据源 |
| 部署灵活性 | 支持本地/公有云/私有云/混合部署 | 仅限云部署(Azure、AWS、GCP) |
| 湖仓支持 | 支持高性能实时和批处理湖仓场景 | 湖仓架构先驱;优化分析型而非运营型工作负载 |
| 多模态数据支持 | 支持多种数据类型和模型,无需重复或映射,包括关系型、键值型、文档型、文本型、对象型、数组型等。 | 针对转换为 Delta Lake 格式的数据进行了优化 |
| 低代码/无代码接口 | 带有内置低代码和无代码工具的统一用户界面 | 主要是代码优先;通常需要 Spark 专业知识和脚本;最低限度的低代码支持 |
| 大规模性能表现 | 在关键任务、高度受监管的行业(如医疗、金融、政府)中,针对操作、分析和实时操作分析工作负载的大规模极高性能已得到充分验证 | 使用 Photon 可为分析工作负载提供高性能;但未针对低延迟用例进行优化。 Neon DB 的大规模性能问题。 |
| 运维简易性 | 一体化平台和服务简化了部署、配置和管理 | 需要手动设置集群、作业和编排管道 |
| 安全&治理 | 虚拟与持久化数据内置治理和安全功能;拥有针对医疗、政府和金融服务的特定行业功能 | 通过 Unity Catalog 进行内置治理;需要复杂的设置 |
| 实时数据流/数据摄取 | 原生支持实时数据源;对实时数据的摄取和并发分析延迟极低 | 提供结构化数据流和自动加载器;分析处理实时数据时延迟较高 |
| 模型部署/ MLOps | 可将任何框架(包括 Databricks)中的模型直接操作到实时连接的工作流中 | 通过与开源 MLflow 集成,提供端到端 ML 生命周期支持 |

互补,而非竞争
InterSystems 和 Databricks 针对不同的角色和工作负载进行了优化。 许多企业选择将它们结合起来使用,以实现最大价值:
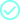
InterSystems 作为可信、受控的实时数据层,统一整个企业的数据,无需重复建设,使数据为人工智能和分析做好准备。
Databricks 由云原生计算和协作笔记本提供支持,用于大规模构建和训练模型。
InterSystems 将 Databricks 中开发的模型应用于实时、高度连接的工作流中,并对实时数据做出反应。
InterSystems 和 Databricks 共同实现了从原始数据到实时人工智能决策和行动的完整流程。
InterSystems 和 Databricks
InterSystems 和 Databricks 实现了从原始数据到实时人工智能驱动决策和行动的完整流程。

咨询专家
让我们为您的企业设计一个数据平台,赋能实时AI就绪洞见。